 SysADMINsLife Admin Blog | Linux Blog | Open Source Blog
SysADMINsLife Admin Blog | Linux Blog | Open Source Blog
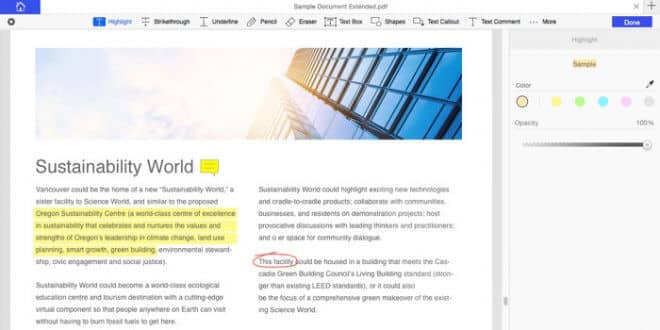
Viele PDF Manager haben heute OCR schon direkt integriert. Meistens sind dies zwar kostenpflichtige Programme, doch es gibt auch wirklich preisgünstige Tools für Privatanwender wobei Firmen. Wir stellen euch heute PDFelement von Whondershare noch kurz vor, wollen aber vor allem auf die Technik der optischen Texterkennung eingehen. Ihr lernt heute also was und bekommt Tipps, wie ihr im Alltag ganz einfach eine OCR verwenden könnt.
Die optische Texterkennung ist eine wundervolle Sache. Wer schon einmal einen ewig langen Text selber abgetippt hat, nur weil er in digitaler Form nicht vorhanden ist, der weiß, wovon wir hier schreiben. Völlig egal, ob es sich dabei um alte Zettel und Briefe handelt oder um ein alter Textdokument, das einfach nicht mehr kompatibel ist. Auch Formate, aus denen man keinen Text kopieren kann oder Bilder, die mit Text versehe sind, fallen in diese Kategorie. Man hat zwei Möglichkeiten: Abtippen von Hand oder eben eine OCR-Software drüber laufen lassen. Diese sogenannte Optical Character Recognition ist sehr beliebt geworden, sogar im privaten Bereich. Es ist nicht mehr so teuer wie einst früher und ist nicht mehr nur für Firmen erschwinglich geworden. So inkludiert zum Beispiel der PDF Manager von Whondershare – PDFelement – ab Werk eine OCR, die sogar sehr akkurat arbeitet.

Optische Texterkennung: Die Magie dahinter
Wie kann es möglich sein, dass eine bloße Software binnen Sekunden und Minuten ein riesiges Bild auf Text durchsucht, die Buchstaben extrahiert und sogleich in ein beschreibbares Dokument umwandelt? Das bedurfte vor einigen Jahren noch irrsinnig teure Tools oder ganze Computer, die darauf spezialisiert waren.
Nun, im Prinzip ist es keine Magie und auch keine aufwendige Software mehr. In nur drei Schritten können heutige Programm in allerlei Anwendungszwecken die richtigen Zahlen, Textzeichen und Buchstaben erkennen. Zunächst scannen diese Tools das ganze Blatt ab und blenden weiße Stellen ohne Text aus. Zuvor muss dem Tool natürlich ein Bild einer Kamera oder eines Scanners gefüttert worden sein. In einem zweiten Durchlauf wird noch mit einer gewissen Auflösung jeder Pixel analysiert. Ist er schwarz oder weiß? Somit ergeben sich Textzeichen, die zunächst als Datensatz gespeichert werden. Erst in einem dritten Gang wird das Ganze für User praktikabel. Denn nun erfolgt der Export als Textdatei oder PDF. Manche Programme können auch einen HTML Code aus dem Text produzieren.

PDFelement kommt mit OCR
Beim Programm PDFelment von Whondershare kommt ebendiese OCR als normales Feature standardmässig im Funktionsumfang mit. Der Nutzer kann den Text erfassen lassen und sogleich als manipulierbare Datei exportieren lassen. Den Rohtext kann man sich auch direkt in ein PDF spielen lassen, falls man nichts mehr verändern möchte. Whondershare wirbt zudem mit den Worten „Automatische Erkennungstechnologie verwandelt alte Office-Dokumente in interaktive Formulare!“ Man kann also zum Beispiel aus einem uralten Word-Dokument ein modernes interaktive bearbeitbares Dokument machen. Das ist schon genial. Und natürlich fallen in Zukunft sämtliche Abtipparbeiten völlig flach. Nie wieder Zettel abschreiben, nur weil man sie nicht digital hat.
PDFelement steht für macOS auf Apple Computern und natürlich auch für Windows auf der Homepage zum Download bereit. Ihr könnt zunächst eine Trial Version herunterladen, um das Programm auf die Probe zu stellen. Später ist immer noch der Kauf einer Vollversion möglich.
